Skip to main contentSupply Chain Analysis Workflow
This documentation explains how to create a workflow that analyzes Apple’s supply chain dependencies by extracting entities and relationships from a PDF report document and generating an interactive graph visualization as well as a LLM-based graph analysis.
You can learn more on how our workflow works: Workflow Concepts
Overview
The workflow processes a PDF report about Apple’s supply chain, extracts key entities (countries, regions, suppliers, components), identifies relationships between them, and generates a graph with explanatory summary. This helps visualize complex supply chain dependencies and geographical distributions of Apple’s manufacturing network.

Step-by-Step Instructions
1. Upload the Apple supply chain analysis pdf
First, retrieve the pdf document from here https://www.aei.org/wp-content/uploads/2025/06/RPT_Miller_Apple-Supply-Chain_June-2025.pdf?x85095, and upload it in you data storage. Give your pdf a descriptive name like apply-supply-chain.pdf
2. Create a New Workflow
Create Start by creating a new workflow in the web interface. Give it a descriptive name like “Apple Supply Chain Analysis”.a new workflow in the web interface. Give it a descriptive name like “Apple Supply Chain Analysis”
Lear more on how to create a workflow here: Create a workflow
Learn more on our nodes concepts here: Workflow Nodes
3. Add S3 File Loader Node
First, we need to load the PDF document from storage.
- Create a new S3LoadFile node
- Configure the node parameters:
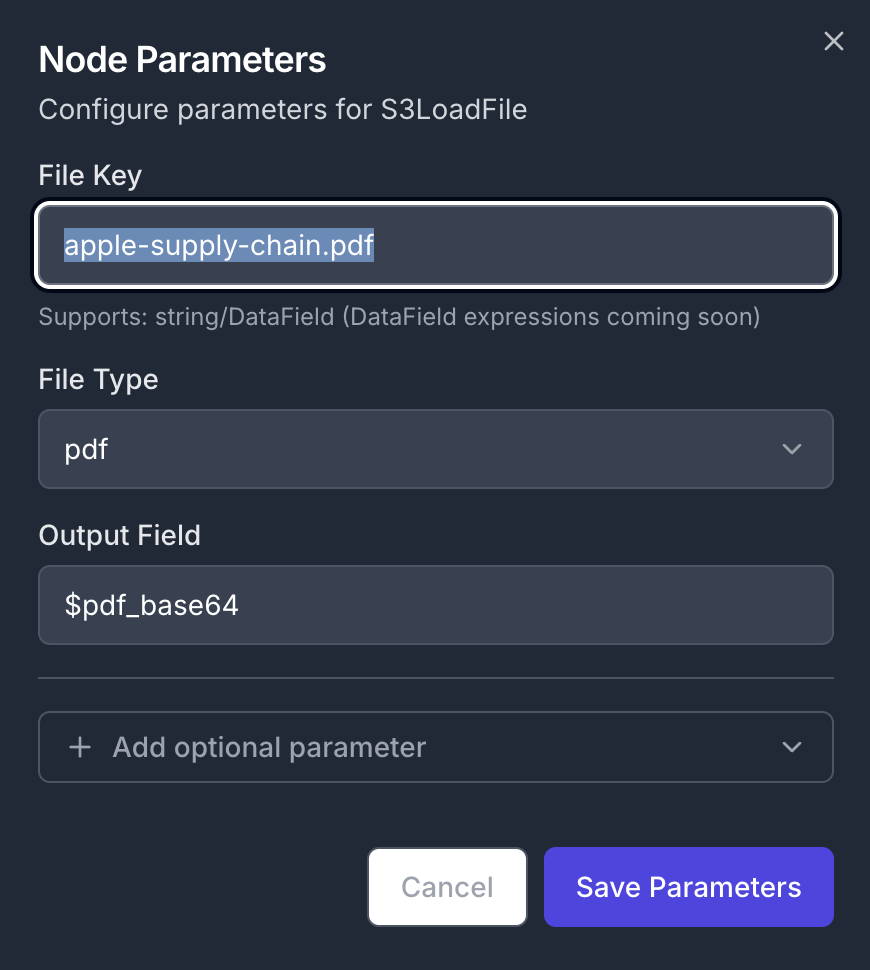
- Output Field:
$pdf_base64
- File Key:
apple-supply-chain.pdf
- File Type:
pdf
 Next, extract text content from the PDF file.
Next, extract text content from the PDF file.
- Add an ExtractTextPDF node to the canvas
- Configure parameters:
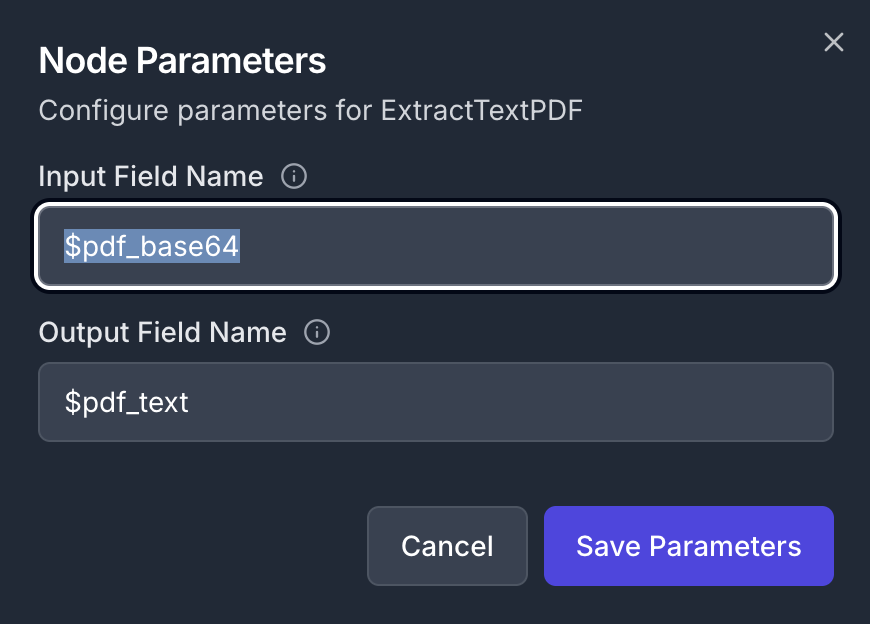
- Input Field:
$pdf_base64
- Output Field:
$pdf_text
 Add intelligent entity extraction to identify key supply chain components.
Add intelligent entity extraction to identify key supply chain components.
- Add a MistralEntityExtractor node
- Configure parameters:
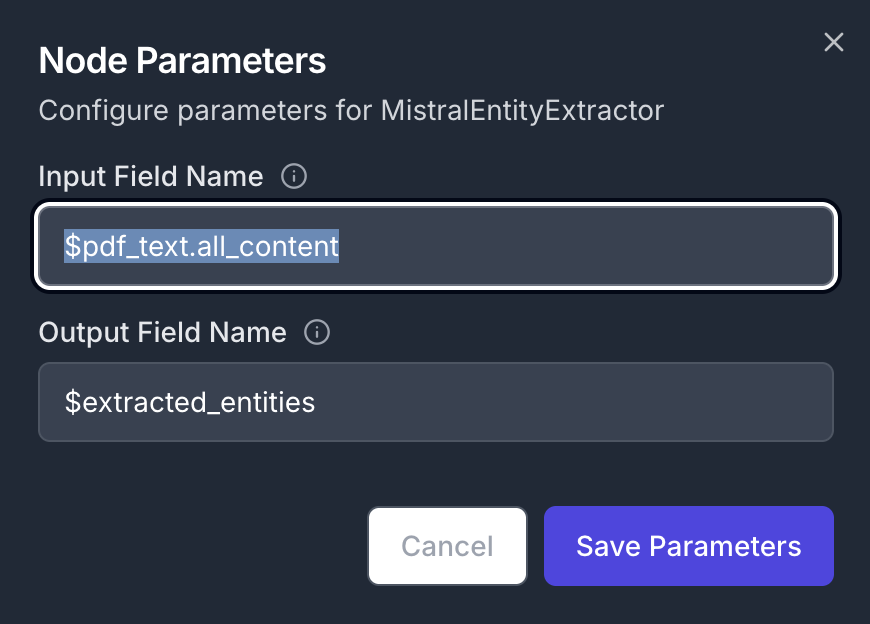
- Input Field:
$pdf_text.all_content
- Output Field:
$extracted_entities
6. Add GML Graph Generator
Convert extracted entities into a graph format.
- Add a GmlGenerator node
- Configure parameters:
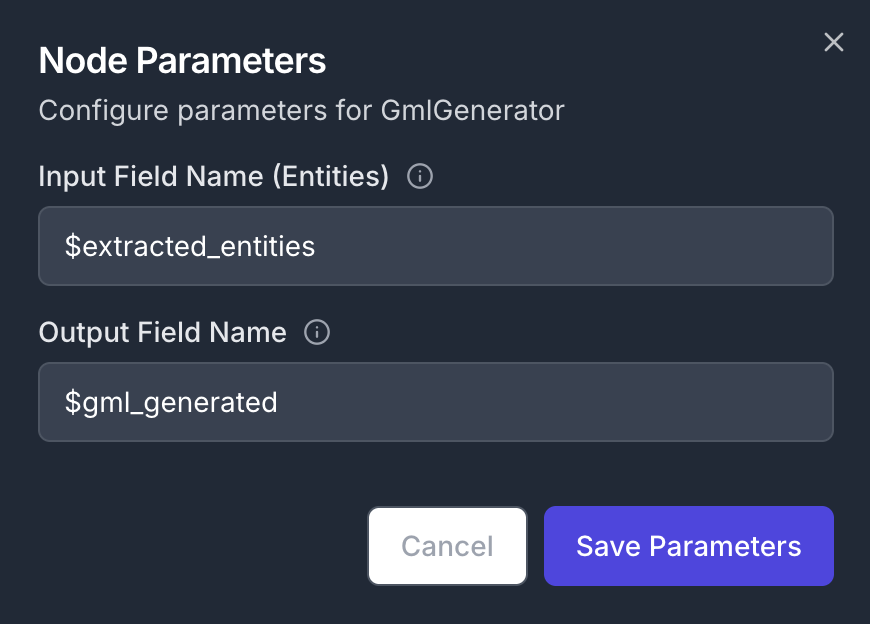
- Input Field:
$extracted_entities
- Output Field:
$gml_generated
7. Add Graph Explanation Node (Optional)
Generate human-readable explanations of the graph structure.
- Add a MistralGraphExplainer node
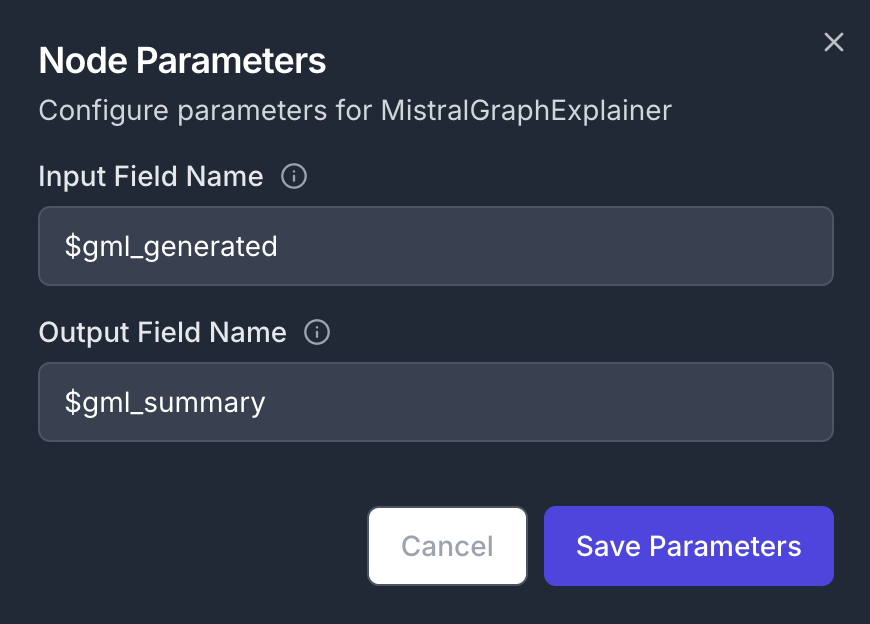
- Configure parameters:
- Input Field:
$gml_generated
- Output Field:
$gml_summary
8. Complete All Connections
Ensure all nodes are properly connected in sequence:
- S3LoadFile → ExtractTextPDF
- ExtractTextPDF → Entity Extractor
- Entity Extractor → GML Generator
- GML Generator → Graph Explainer
Your workflow will look like this:

9. View your graph in the TuringDB visualizer
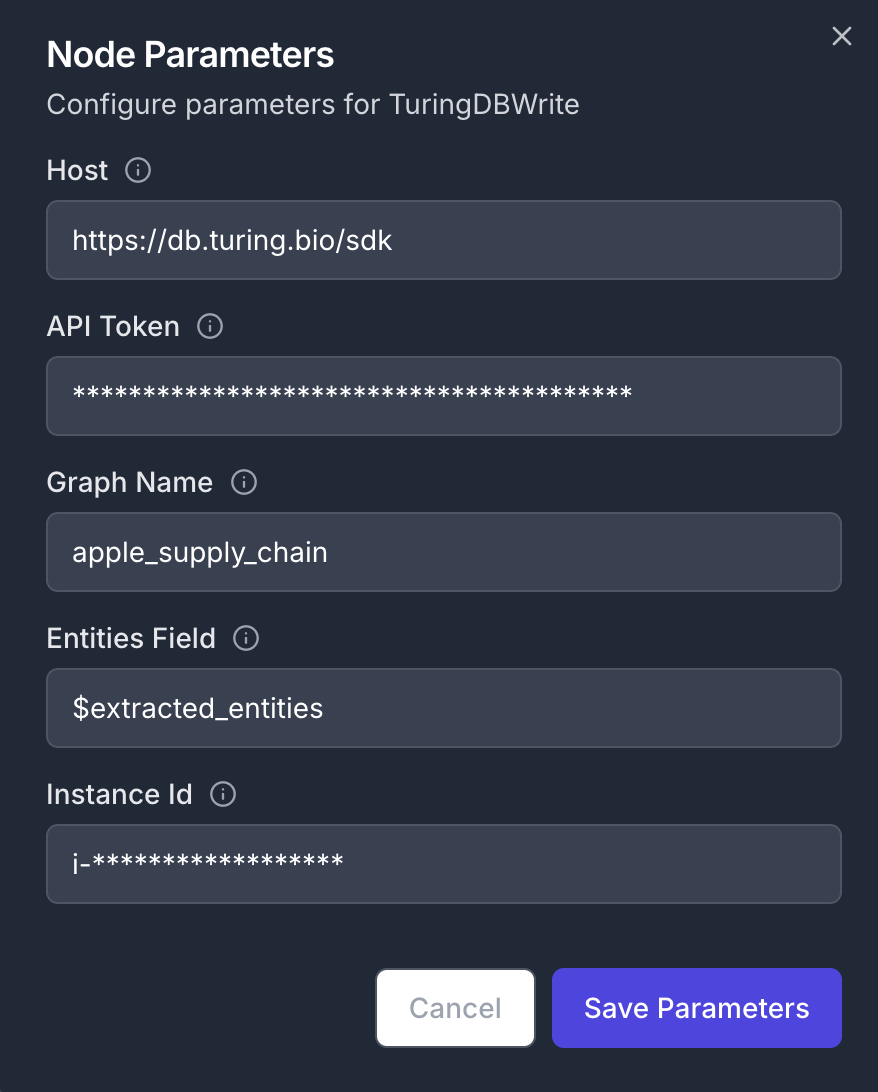
If you have a running TuringDB instance, create a new graph containing the extracted entities. To do so, add a new TuringDBWrite node and connect it to the output of the MistralEntityExtractor node. To configure the node, you will need to supply a graph_name, an API token and the ID of the running instance.
To find you API Token and instance ID check
Authentication
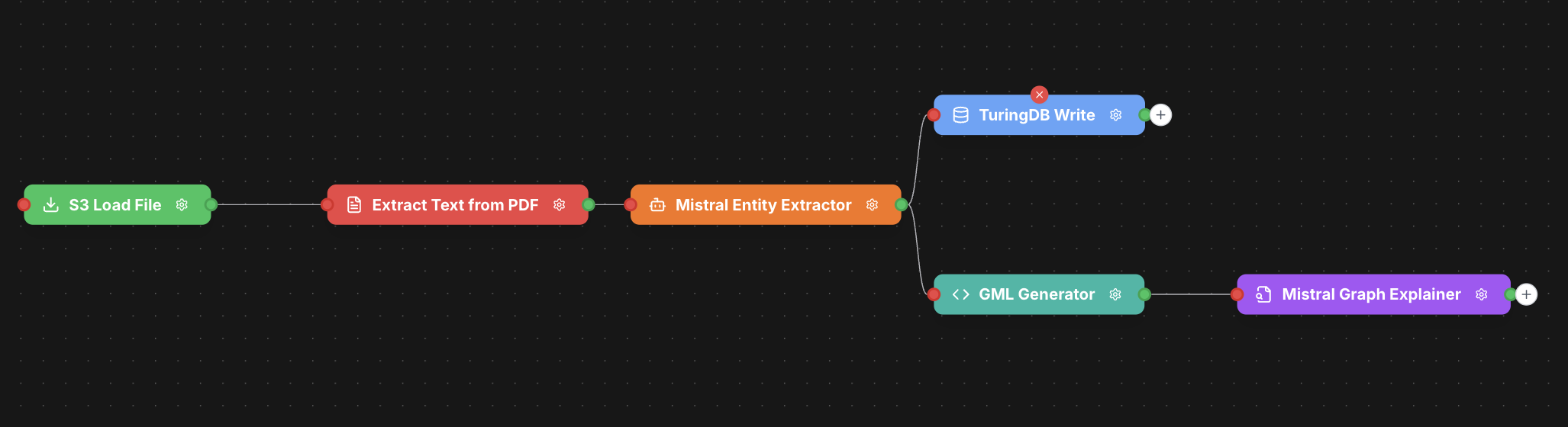
 Your final pipeline will look like this
Your final pipeline will look like this
Running the Workflow
Learn more on running workflows: LINK
1. Validate Configuration
Before running, ensure:
- All nodes have required parameters filled
- All connections are properly established
- The PDF file exists in your S3 storage
2. Execute the Workflow
- Click the Execute Workflow button
- Monitor execution progress in the status panel
Show Image_Figure 12: Workflow execution in progress_
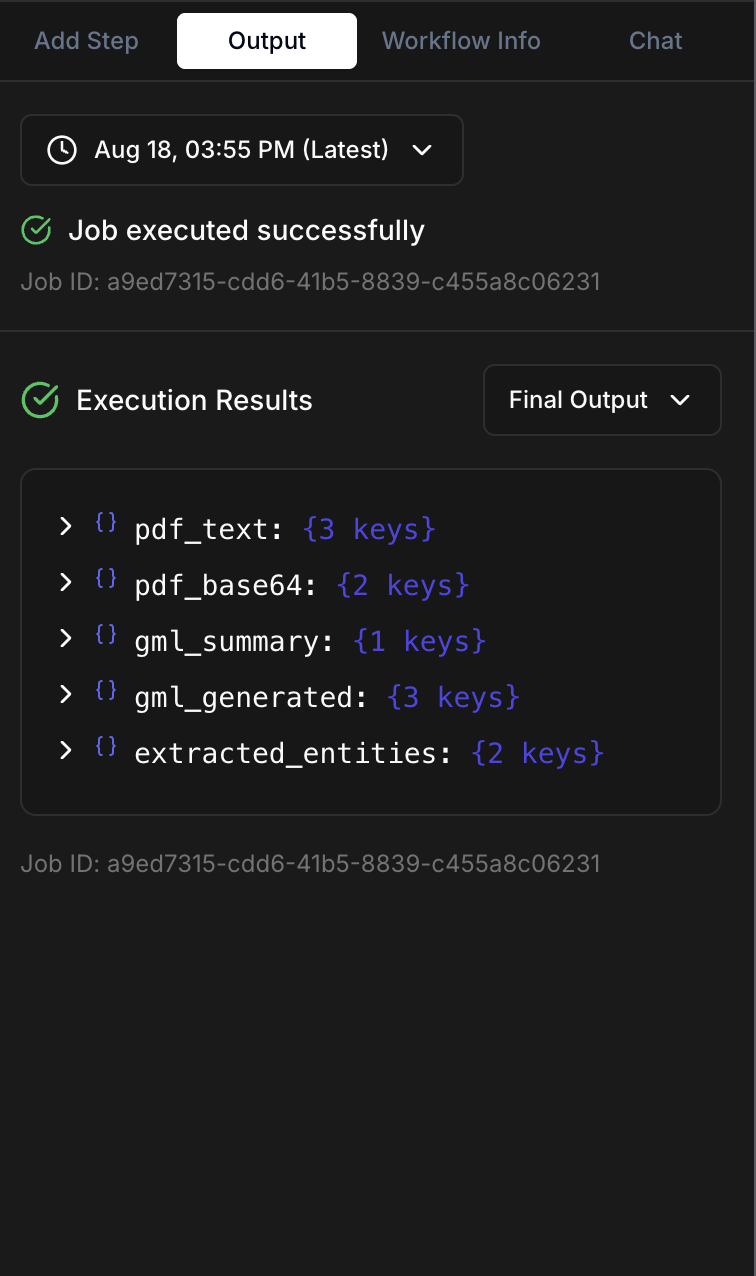
3. View Results
Once complete, the output panel will display the JSON data generated by the pipeline, including the content of the gml file that you can read using a graph rendering software (like cytoscape). Optionally, if you added a TuringDBWrite node, you can visualize the resulting graph in the TuringDB visualizer.
Troubleshooting
Common Issues:
- PDF Loading Errors: Verify file exists and user has access permissions
- Text Extraction Failures: Ensure PDF is not password-protected or corrupted
- Entity Extraction Issues: Check that extracted text contains relevant content
- Connection Errors: Verify all node connections are properly established
- TuringDB Errors: Make sure the supplied instance is valid and that you have access to it
If you are having any trouble contact us: Troubleshooting
More info on Workflows
Workflow Concepts
Build Workflows
Workflow Nodes
Get Workflow Results
Workflows Exemples
We will very soon release our Python workflows manager in open source
Workflows in Python