TuringDB has eliminated the plague of read locks.Documentation Index
Fetch the complete documentation index at: https://docs.turingdb.ai/llms.txt
Use this file to discover all available pages before exploring further.
Our architecture is designed from the ground up to deliver true snapshot isolation—without sacrificing performance or scalability.
The Problem with Traditional Databases
In most RDBMS systems, read queries are blocked by write operations. This means:- Analytics pipelines stall during ingestion
- Dashboards freeze under concurrent load
- AI workloads suffer from stale or delayed data access
TuringDB’s Zero-Lock Architecture
TuringDB rewrites the rules.- Every read transaction executes on its own immutable snapshot of the graph.
- Writes never block reads, and reads never interfere with writes.
- Snapshot Isolation is enabled by default, with no coordination cost.
- Built-in support for massive parallelism, powering:
- Real-time dashboards
- AI pipelines
- Batch analytics
How It Works
When a write query modifies the database, it creates a new snapshot behind the scenes. Read queries simply operate on whichever snapshot they start from—no locks, no contention. This ensures:- Consistent reads at a fixed point in time
- Concurrent write throughput without coordination bottlenecks
- Scalable multi-user workloads
Architecture Comparison
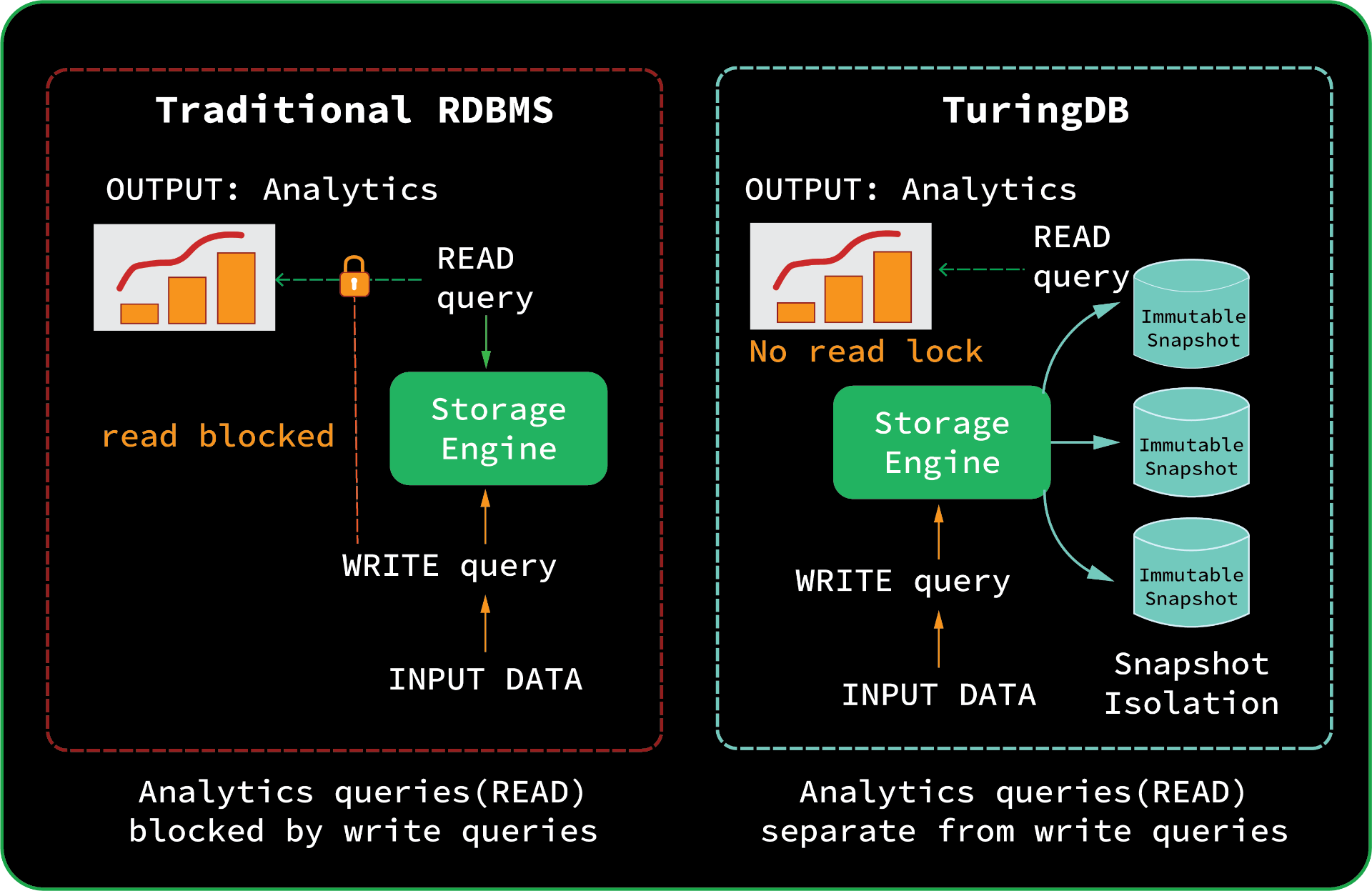
In TuringDB, analytics never wait. Read and write paths are completely decoupled.
Summary
| Feature | Traditional RDBMS | TuringDB |
|---|---|---|
| Read blocks on write | Yes | Never |
| Snapshot isolation | Manual or expensive | Default & efficient |
| Concurrency under load | Bottlenecked | Massively parallel |
| Built for real-time graphs | No | Yes |
TuringDB gives you instant analytics with zero locking, enabling a new class of real-time, high-frequency applications at scale.